KI in der Industrie: Modelle trainieren mit kleinen Datensätzen
Übliche Praktiken zum Trainieren von Machine-Learning-Modellen beruhen auf grossen Datenmengen – diese sind in der Fertigungsindustrie aber oft nicht vorhanden. Datenzentrierte KI stellt einen neuen Ansatz dar, der es auch produzierenden Unternehmen ermöglichen soll, KI-Systeme erfolgreich einzusetzen.

Der Einsatz von Künstlicher Intelligenz (KI) in der Wirtschaft wächst und birgt ein ungemeines Potenzial für optimierte Geschäftsprozesse und neue, innovative Geschäftsmodelle. Gerade Tech-Giganten wie Google, Apple oder Meta (ehemals Facebook) zeigen immer wieder eindrücklich, was mit KI möglich ist. Kein Wunder: Solche Plattform-Giganten und Grosskonzerne haben Zugriff auf schier unerschöpfliche Datenquellen – gängige Deep Learning Algorithmen erreichen unter diesen Bedingungen ausgezeichnete Resultate. Big Data lässt grüssen.

Mehr als KI: Das sind die wichtigsten IT-Trends 2024

“An AI agent has to undergo a probationary period”
“An AI agent has to undergo a probationary period”
«Ein KI-Agent muss zwingend eine Probezeit durchlaufen»
In vielen Branchen und Unternehmen ist die Realität aber eine andere: Sie verfügen nicht über Unmengen an Daten, um bestehende Machine-Learning-Modelle ausreichend füttern und nutzbringend einsetzen zu können. Das trifft oft auch auf Fertigungsunternehmen zu: «Im Zusammenhang mit KI steht die Industrie vor ganz spezifischen Herausforderungen», hält Francesco Spadafora, Software-Ingenieur für Embedded Applications bei bbv, fest. «Oftmals sind nur kleine Datensätze vorhanden und es sind hohe Kosten erforderlich, um Maschinenanlagen mit weiteren Sensoren auszustatten; oder die Qualität der zur Verfügung stehenden Daten ist nicht gut genug, um Machine-Learning-Modelle richtig trainieren zu können.»
Soll KI beispielsweise zur Erkennung von Produktionsmängeln eingesetzt werden, wird das Trainieren des Algorithmus zur regelrechten Herkulesaufgabe: Da Produktmängel nur selten auftreten, verfügen die meisten Hersteller nicht über Millionen, Tausende oder gar Hunderte von Beispielen eines bestimmten Fehlertyps, den es auszumerzen gilt. Auch können nicht ohne grossen Aufwand mehr Daten generiert werden.
«Data centric AI»: Qualität statt Quantität
Andrew Ng erkannte die Herausforderungen, denen sich Fertigungsunternehmen bei der Einführung von KI-Verfahren stellen müssen. Ng ist einer der prominentesten Persönlichkeiten im KI-Sektor: Er war einer der Gründer und Leiter des Google-Brain-Projekts für Deep-Learning-Techniken, arbeitete bei der chinesischen Suchmaschinenfirma Baidu und verpflichtet sich heute als CEO seines Start-ups Landing AI voll und ganz der Umsetzung von KI-Projekten im Industriesektor. Auch er sah, dass sich die KI-Praktiken der Big-Tech-Konzerne nicht eins zu eins auf die Fertigungsindustrie übertragen lassen.
Deshalb plädiert Ng für die «data centric AI» – einen datenzentrierten Ansatz zum Trainieren von Machine-Learning-Modellen. Anstatt zu versuchen, diese auf den jeweils vorhandenen Datensatz zu optimieren, ist die Ausgangslage hier eine ganz andere: Von vorherein werden einige Modelle mit Parametern festgelegt. Deren Vorhersagen werden in der datenzentrierten Analyse schliesslich bewusst genutzt, um die Datenqualität zu steigern. Der datenzentrierte KI-Ansatz zielt also auf den Aufbau von KI-Systemen mit qualitativ hochwertigen Daten ab. Laut Ng habe sich die datenzentrierte KI bereits in der Praxis bewährt: Eine deutliche kürzere Zeit zur Implementierung von KI-Anwendungen sowie eine bessere Datenausbeute und Genauigkeit seien auf den Ansatz zurückzuführen.
Doch: Wie geht man vor, um seine Daten für die einzusetzenden Machine-Learning-Modelle zu optimieren? bbv orientiert sich hier am datenzentrierten KI-Ansatz, setzt aber bei den Business-Anforderungen an:
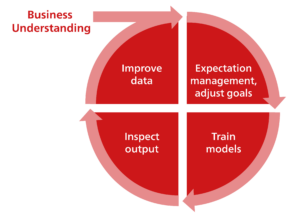
Im Folgenden werden die vier Phasen des Entwicklungsmodells erläutert.
Geschäftsverständnis (Business Understanding)
Ähnlich wie beim CRISP-DM-Modell erfordert auch der datenzentrierte KI-Ansatz zuerst ein grundlegendes Business-Verständnis und Domänenwissen. Womit verdient mein Unternehmen Geld? Was sind die Herausforderungen in der Produktion? Gerade im produzierenden Gewerbe sind diese Fragestellungen zentral für eine zweckdienliche KI-Lösung: «In der Industrie sind viel mehr Gespräche über das eigene Geschäftsmodell und den Mehrwert von KI-gesteuerten Prozessen nötig als in Digitalkonzernen», sagt Cedric Klinkert, Embedded Software Engineer bei bbv. «Der Initialaufwand zur Datenerfassung ist in der Industrie hoch – gerade wenn noch keine solide Datenstrategie vorhanden ist und zusätzliche Sensorik benötigt wird. Dies führt auch oft dazu, dass man nur kleine Datensätze hat, mit denen man arbeiten muss.»
Zielvereinbarung (Expectation Management & Adjust Goals)
Anschliessend muss geklärt werden, welche Probleme mit der KI-Lösung überhaupt angegangen werden sollen. Manchmal sind hier mehrere Iterationen notwendig, bis wirklich realistische Business-Ziele ausgearbeitet wurden: «Laut einer Gartner-Studie aus dem Jahr 2017 scheitern 85 Prozent der Data-Science-Projekte – oft auch, weil sich Unternehmen zu viel davon erhoffen», sagt Spadafora. «Man muss mit allen Stakeholdern sprechen, Erwartungen eichen und priorisieren und auf eine Infrastruktur hinarbeiten, die es einem erlaubt, die richtigen Daten sammeln zu können.»
Modelle trainieren (train models)
Basierend auf dem Problem, das mittels KI gelöst werden soll, schlagen wir vor, eine Handvoll Modelle zu definieren. Diese werden im Verlauf des Verfahrens nicht geändert. In diesem Schritt werden sie anhand passender Methoden trainiert und mittels geeigneter Metriken evaluiert.
Modelle untersuchen (inspect output)
Anhand des KI-Trainings werden die Resultate hinterfragt und die eingesetzten Daten inspiziert. Dabei lohnt es sich, Randfälle, Ausreisser oder falsch klassifizierte Daten nochmals genauer anzuschauen. Am besten mithilfe von visueller Inspektion und qualitativer Analyse. Diese Erkenntnisse dienen als Grundlage für den nächsten Schritt.
Daten überarbeiten (improve data)
Anhand der gewonnenen Erkenntnisse werden die Daten neu aufbereitet. Auch können neue und gezielte Daten hinzugezogen werden, um die fehlenden Aspekte zu decken. Hier ist ebenfalls Domänenwissen gefragt, um die verfügbaren Rohdaten richtig aufzubereiten und jene Merkmale zu extrahieren, mit denen das KI-System verbessert werden kann (Feature Engineering). «Gerade weil nur kleinere Datensets verwendet werden, können diese im Detail analysiert und optimiert werden», stellt Cedric Klinkert fest.
Mit Innovation Workshops ins Thema einsteigen
Dank datenzentrierter KI sind auch kleinere Unternehmen in der Lage, erfolgreiche KI-Cases umzusetzen – weil das iterative Vorgehen genau darauf abzielt, mit den wenigen Daten zu beginnen und erst wenn nötig neue Daten hinzuzuziehen, die für den eigenen Business-Case tatsächlich relevant sind. Doch wie sieht dieser nun aus? bbv verfügt über jahrelange Erfahrung in der Umsetzung von Embedded-Systemen und IoT-Projekten – und über Know-how im Machine Learning: «Auch unsere Innovation Workshops eignen sich, um die Erwartungen des Kunden abzuholen und daraus erste Handlungsfelder für KI aufzuzeigen», sagt Francesco Spadafora. «Mit dem Domänenwissen des Kunden und unserer Expertise, neue und vor allem richtige Daten zu generieren, verhelfen wir ihm schliesslich auch bei der weiteren Umsetzung – vom ersten Proof of Concept bis zum umfassenden Business Case.»

Der Experte
Francesco Spadafora
Francesco Spadafora war Software-Ingenieur bei bbv für Embedded Applications im Bereich Industrie und Medizintechnik. Während seines Studiums befasste er sich mit der Analyse von Daten aus Sensornetzwerken. Seither glaubt er, dass der nächste Schritt in der Innovation darin besteht, Systeme und Abläufe anhand der Erkenntnisse aus Daten besser zu verstehen.

Der Experte
Cedric Klinkert
Dr. Cedric Klinkert ist Software-Ingenieur bei bbv für Embedded Applications im Bereich Industrie und Medizintechnik. In seiner Doktorarbeit erforschte er neuartige Materialien für Transistoren mithilfe von rechenintensiven high-throughput Simulationen. Bei der Analyse dieser Daten beschäftigte er sich vertieft mit den Methoden des maschinellen Lernens. Die gewonnenen Erkenntnisse bestärkten ihn in seiner Überzeugung, dass durch KI neue Blickwinkel auf Systeme aufzeigt werden, die es zu nutzen gilt.
Data Science Innovation Workshop
Mit unserem dreiteiligen Workshop können Sie die Potenziale und Risiken im Bereich Data Science schneller und besser einzuschätzen. Dabei unterstützen wir Sie ganz individuell mit unserer Prozess-, Methoden-, Technologie- und Business-Expertise. Gemeinsam entwickeln wir die vielversprechendsten Ideen zu einem belastbaren Business Case, so dass sie direkt realisierbar werden.

