Ein Level-Up für die Skalierung in Kubernetes
Moderne Container-Anwendungen sind oftmals von einer Vielzahl an Komponenten abhängig und müssen auf externe Ereignisse reagieren können. Mit KEDA steht ein praktisches Tool zum Skalieren flexibler Workloads in Kubernetes bereit. Ein Überblick.

Mit dem Horizontalen Pod Autoscaler (HPA) bietet Kubernetes ein built-in-Feature, welches Pods basierend auf der CPU- oder RAM-Auslastung skalieren kann. Für moderne Applikationen ist das ein guter Anfang; doch gerade verteilte Anwendungen haben oft mehrere Komponenten bzw. Abhängigkeiten ausserhalb des Kubernetes Clusters – etwa ein Azure Service Bus, eine Cassandra-Datenbank, MongoDB oder Elasticsearch.

Wie Webentwickler Komplexität reduzieren

Mit IoT ins Reich der Mitte

An API-Gateways führt kein Weg vorbei

Microservices vs. Serverless Computing
Erweiterte Skalierung mit KEDA
An dieser Stelle kommt das «Kubernetes Event-driven Autoscaling» – kurz KEDA – ins Spiel. Bei KEDA handelt es sich um ein Kubernetes-Tool, mit dem man Anwendungen entsprechend von Ereignissen, die innerhalb oder ausserhalb eines Kubernetes-Clusters auftreten, skalieren kann. Dazu werden mithilfe von KEDA verschiedene Scaler erstellt. Also benutzerdefinierte Ressourcen in Kubernetes vom Typ ScaledObject, die auf die zu skalierenden Deployments oder StatefulSets referieren. Diese vorgefertigten Scaler werden mit KEDA ganz einfach in einen bestehenden Kubernetes Cluster integriert. Sie überwachen die konfigurierten externen Quellen und skalieren die Pods der Anwendung.
Ein Beispiel: Ein Onlineshop nimmt am Black Friday hunderte oder tausende Bestellungen entgegen. Diese Bestellungen werden in einer Queue gespeichert und dann verarbeitet. Die Anwendung, welche die Nachrichten verarbeitet, sollte in diesem Fall mit KEDA skaliert werden, um eine zeitnahe Verarbeitung aller Bestellungen gewährleisten zu können. Hier stösst der HPA an seine Grenzen, da die Pods nicht anhand der Metriken dieser Komponenten skaliert werden können.
KEDA ist ein Projekt der Cloud Native Computing Foundation (CNCF) und wird regelmässig mit Updates versorgt. Die grössten Unterstützer sind Microsoft und Red Hat. Die Community Meetings, die rund alle zwei Wochen via Zoom stattfinden, sind öffentlich und jeder Interessierte kann daran teilnehmen. Die Roadmap für zukünftige Features und aktuelle Probleme werden auf der GitHub-Seite von KEDA veröffentlicht.
Die Architektur von KEDA
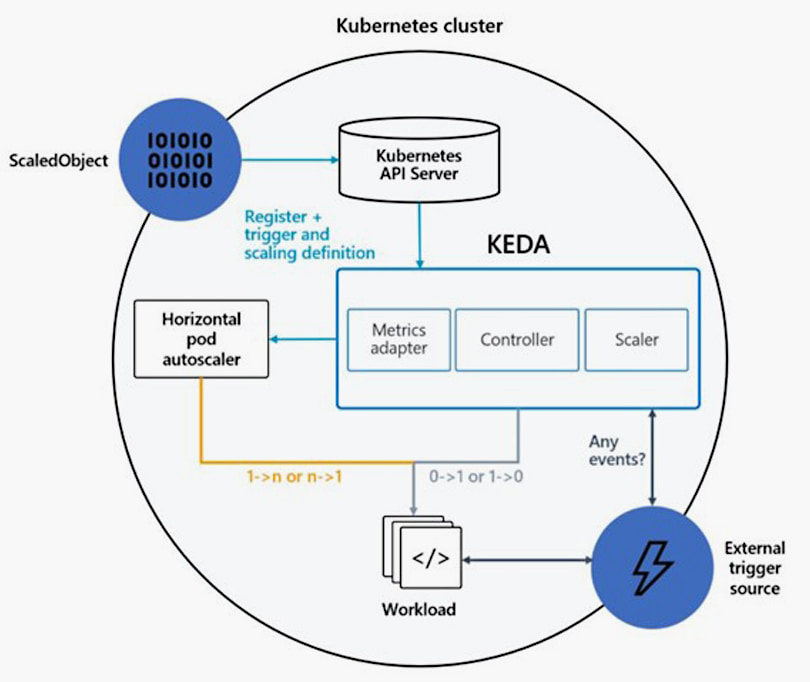
Um Anwendungen skalieren zu können, übernimmt KEDA folgende Aufgaben:
- Deployment Agent
- Kubernetes Metrics Server
Der Deployment Agent aktiviert bzw. deaktiviert bestehende Kubernetes-Deployments, um die assoziierten Pods zu skalieren. Die Mindest- und Maximalanzahl der Pods kann in der Konfiguration des Autoscalers eingestellt werden. KEDA fungiert aber auch als Kubernetes Metrics Server und kann über einen Adapter dem HPA umfangreiche Ereignisdaten liefern – etwa die Anzahl an Nachrichten in einer Queue oder neue Daten in einer Datenbank. Durch diese Integration kann der HPA bestehende Deployments skalieren, ohne dass die Anwendung oder die Konfiguration angepasst werden müssen.
Ein weiterer Vorteil: Mit KEDA lassen sich Deployments oder Jobs auf 0 laufende Pods skalieren («scale to 0») – was für jene Anwendungen Sinn macht, die auf externe Ereignisse wie Nachrichten in einer Queue reagieren müssen und nicht zeitkritisch sind. War dieses Feature zuvor nur aus Function-as-a-Service (FaaS) wie Azure Functions oder AWS Lambda bekannt, steht es dank KEDA nun auch für Kubernetes zur Verfügung. Dadurch können noch mehr Ressourcen als mit einer standardmässigen Kubernetes-Distribution eingespart werden.
Einfache Integration
KEDA ist eine besonders leichtgewichtige Komponente, deren einzige Aufgabe das Skalieren von Pods ist. Der Autoscaler lässt sich sehr einfach über ein Helm Chart installieren (wobei das Helm Chart im Namespace keda installiert werden muss) und läuft auf jeder CNCF-zertifizierten Kubernetes-Distribution. Offiziell wird jede Kubernetes-Version ab 1.16.0 unterstützt. Die Community und die KEDA Maintainer haben bis Anfang 2022 bereits mehr als 40 integrierte Scaler entwickelt. Diese können einfach mit Umgebungsvariablen oder Kubernetes Secrets konfiguriert werden, wodurch die Integration in wenigen Schritten erfolgen kann.
Fazit
KEDA ist ein grossartiges Tool zum Skalieren flexibler Workloads in Kubernetes. Es ermöglicht die Auswahl aus einer Vielzahl von vorgefertigten Scalern, wodurch externe Ressourcen wie Azure Monitor oder MongoDB überwacht werden können. Insbesondere das Skalieren auf 0 ermöglicht es, die zugewiesenen Ressourcen auf ein Minimum zu reduzieren und hilft so beim Betrieb eines Kubernetes-Clusters Geld zu sparen.

Der Autor
Wolfgang Ofner
Wolfgang Ofner ist ein Microsoft Certified Trainer und arbeitete als Senior Software Architekt für Azure-, DevOps- und .NET-Lösungen bei der bbv. In diesen Bereichen konnte er in den letzten Jahren diverse Kunden erfolgreich beraten und bei Implementierungen unterstützen.
Dieser Artikel ist eine Zusammenfassung des Beitrags von Wolfgang Ofner im Windows Developer. Lesen Sie hier den vollständigen Artikel und erfahren Sie mehr über das Erstellen und Konfigurieren von Scalern in KEDA.
